No more face mashups: UMO meets Qwen Edit

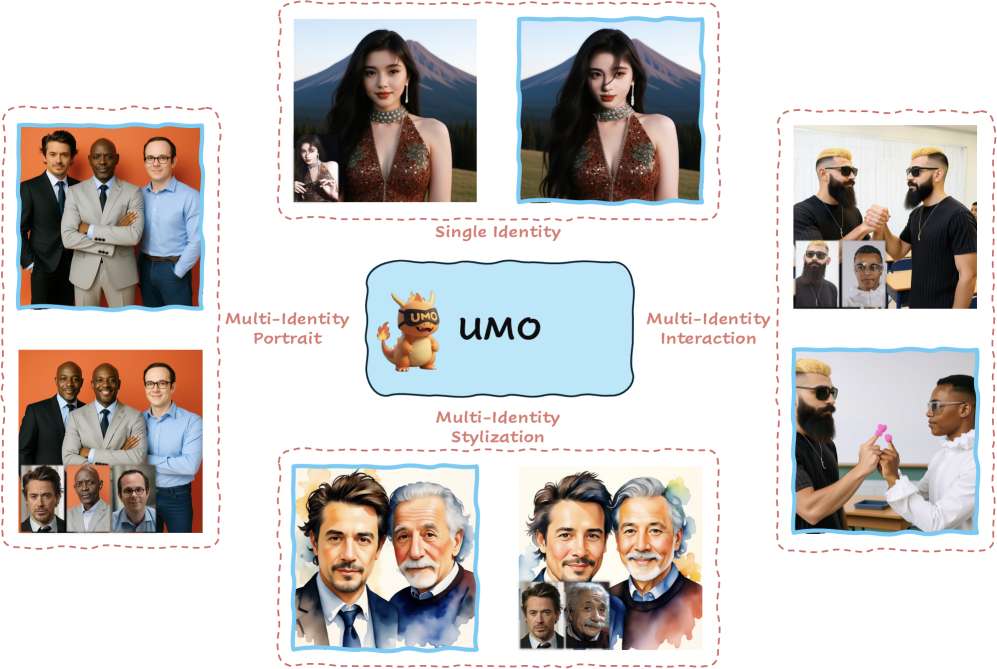
We rebuilt multi‑identity image editing on Qwen Edit around global matching and reward-driven training If you’ve tried to edit images with multiple people, you’ve felt it: faces average together, attributes leak across subjects, and “who’s who?” becomes a guessing game. As the headcount grows, most pipelines crumble. Humans are ultra-sensitive to faces; one-to-one heuristics don’t scale.
The Challenge
Modern AI image editing has mastered the art of the solo portrait. You can conjure a photorealistic CEO or a fantasy warrior from a simple text prompt with stunning fidelity. But add a second or third person to the scene, and the magic often breaks. The core challenge? Maintaining distinct identities.
Current models struggle to keep track of "who's who." When prompted to create an image of multiple specific people, the AI often gets confused. This isn't just about placing people in a scene; it's about preserving the unique facial features, hair color, and characteristics of each individual without them blending together.
Imagine you're trying to generate a photo of three friends: Alice, Bob, and Carol.
1. Facial Averaging and Feature Bleed:
Instead of creating three distinct faces, the AI might produce individuals who look like strange composites of each other. Alice might end up with Bob's jawline, or Carol's nose might appear on Alice's face. The model creates an "average" face that incorporates features from all the references, rather than assigning them correctly. It’s as if the AI took all the source photos and digitally mashed them together, resulting in three vaguely similar, uncanny strangers.
2. Identity Swapping:
Another common failure is "identity swapping." The AI might generate three perfectly clear faces, but it gets their identities mixed up. If your prompt was "Alice on the left, Bob in the middle, and Carol on the right," you might get Bob on the left, Alice on the right, and Carol in the middle. The model understands the features but fails to correctly map them to the positions and descriptions specified in the prompt. This makes it impossible to control the composition of a scene.
3. The "Uncanny Valley" Effect:
Because humans are incredibly sensitive to facial details, even minor errors can make a generated image feel "off" or unsettling. When features are blended or slightly distorted, the resulting faces can fall into the "uncanny valley"—looking almost human, but with subtle inaccuracies that are deeply unnerving. Skin can appear overly smooth and plastic-like, and lighting can feel unnatural, further distancing the image from reality.
Solving this "identity leakage" problem is one of the most significant challenges in generative AI today. It's the barrier that stands between creating simple solo portraits and generating complex, believable scenes with multiple, specific individuals—a critical step for everything from personalized family photos to commercial ad creation.
UMO: A new approach
We integrated UMO (Unified Multi‑identity Optimization) into Qwen Edit to turn this multi-person chaos into crisp, consistent portraits that still follow your prompt and style. UMO reframes multi‑identity generation as a global assignment problem with reinforcement learning on diffusion models—so every generated face matches the best reference face, and non‑matches are actively discouraged. Then we add a final realism‑alignment RL pass to remove the plastic “AI sheen” without sacrificing identity.
How UMO Works ?
We detect faces in the generated image, embed them with a lightweight face encoder, and compute pairwise similarities to the reference faces. The reward boosts the matched edges and penalizes mismatches (MIMR). We apply ReReFL on the late denoising steps only—where identity signals are stable—to align Qwen Edit with these rewards using parameter‑efficient LoRA finetuning. Net result: fewer swaps, higher fidelity, better separation.
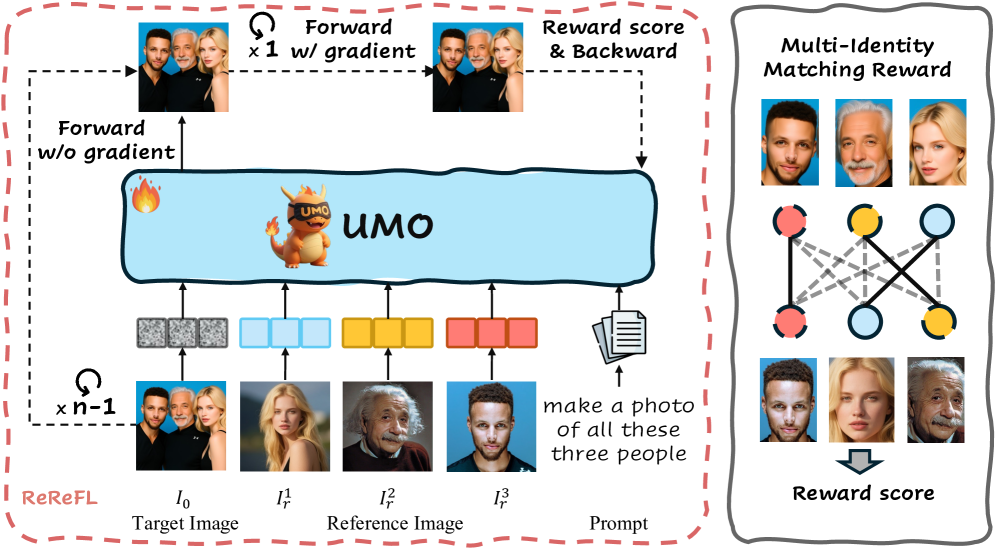
- Multi‑to‑multi matching: Instead of pinning each output face to a single reference, UMO maximizes overall matching quality using a bipartite assignment (Hungarian) step. That balances intra‑identity variation (pose, expression, lighting) with inter‑identity separation.
- Reference Reward Feedback Learning (ReReFL): Late‑step reward optimization on diffusion models—where identity cues stabilize—so gradients are clean and impactful.
- MIMR (Multi‑Identity Matching Reward): Positive signal for matched pairs, negative signal for mismatches. This suppresses cross‑identity leakage and makes each person stand on their own.
What it means for creators ?
- Multi‑person scenes that look like your actual people—not averaged composites.
- Scales from single portraits to 3–5 person compositions, and early wins on crowded scenes.
Qwen Image Edit Training Recipe
- Optimizer: AdamW, learning rate 5e‑6; LoRA rank 512 on attention blocks; effective batch 8 on 8×H100.
- Scheduler: 30–50 denoising steps
- Late‑step RL window: We choose the last ~30–40% of steps where identity reward variance flattens. A typical example:
- If T=30 steps: focus RL on t ∈ [1, 10–12] (where t=1 is the last step).
- If T=50 steps: focus RL on t ∈ [1, 18–20].
- Rewards:
- SIR (single‑identity): cosine similarity in face‑embedding space.
- MIMR (multi‑identity): λ1=+1 for matched pairs, λ2=−1 for non‑matches.
- Loss: total = pretrain loss + (− reward).
- Data: A mix of real multi‑person video frames (with per‑ID retrieval across clips) and filtered synthetic scenes for pose/lighting diversity, all filtered with strict face‑similarity thresholds.
Results

Our Next Big Push: Tackling the “AI Look”
While UMO dramatically improves identity consistency, we know the work isn't done. What we saw in some outputs were tell-tale signs of AI generation: over-smooth skin, uncanny lighting, and subtle plastic textures that break realism.
Fixing this is our top priority, and it's what we are actively working on for our next release.
Our solution is a final, realism-alignment RL stage that will sit on top of the UMO framework. Here’s the plan:
- Realism Reward: This new reward function will be trained on a mixture of human preference labels and a separate realism scorer. It will penalize non-photorealistic textures, unrealistic lighting, and other AI artifacts.
- Identity Guardrails: Crucially, we will keep the MIMR reward active as a guardrail during this phase. This ensures that in our quest for realism, we don't sacrifice the identity fidelity we worked so hard to achieve.
- Low-level Priors: We are also experimenting with auxiliary penalties that target over-smoothing directly by looking at edge and texture statistics in the generated images.
This next phase will bridge the final gap between "consistent" and "indistinguishable from a real photo." Stay tuned for updates.
References
@misc{wu2025qwenimagetechnicalreport,
title={Qwen-Image Technical Report},
author={Chenfei Wu and Jiahao Li and Jingren Zhou and Junyang Lin and Kaiyuan Gao and Kun Yan and Sheng-ming Yin and Shuai Bai and Xiao Xu and Yilei Chen and Yuxiang Chen and Zecheng Tang and Zekai Zhang and Zhengyi Wang and An Yang and Bowen Yu and Chen Cheng and Dayiheng Liu and Deqing Li and Hang Zhang and Hao Meng and Hu Wei and Jingyuan Ni and Kai Chen and Kuan Cao and Liang Peng and Lin Qu and Minggang Wu and Peng Wang and Shuting Yu and Tingkun Wen and Wensen Feng and Xiaoxiao Xu and Yi Wang and Yichang Zhang and Yongqiang Zhu and Yujia Wu and Yuxuan Cai and Zenan Liu},
year={2025},
eprint={2508.02324},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2508.02324},
}
@article{cheng2025umo,
title={UMO: Scaling Multi-Identity Consistency for Image Customization via Matching Reward},
author={Cheng, Yufeng and Wu, Wenxu and Wu, Shaojin and Huang, Mengqi and Ding, Fei and He, Qian},
journal={arXiv preprint arXiv:2509.06818},
year={2025}
}
@article{wu2025omnigen2,
title={OmniGen2: Exploration to Advanced Multimodal Generation},
author={Chenyuan Wu and Pengfei Zheng and Ruiran Yan and Shitao Xiao and Xin Luo and Yueze Wang and Wanli Li and Xiyan Jiang and Yexin Liu and Junjie Zhou and Ze Liu and Ziyi Xia and Chaofan Li and Haoge Deng and Jiahao Wang and Kun Luo and Bo Zhang and Defu Lian and Xinlong Wang and Zhongyuan Wang and Tiejun Huang and Zheng Liu},
journal={arXiv preprint arXiv:2506.18871},
year={2025}
}