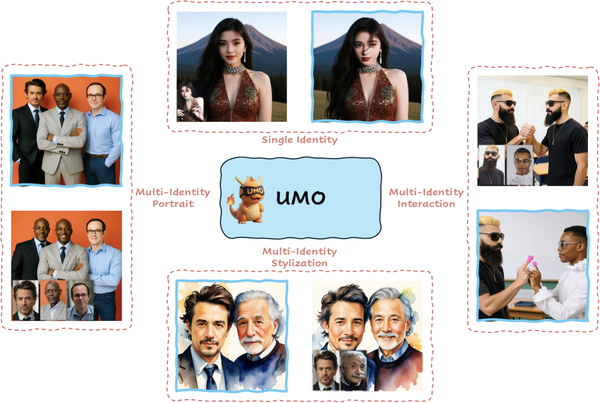
Introducing Hunyuan Keyframe LoRA: Open-Source Keyframe-Based Video Generation


Introduction
In the realm of AI-driven video creation, tools like Runway's Gen-3 Alpha Turbo and Kling have showcased the potential of keyframe-based generation, enabling smooth transitions between specified frames. Inspired by this approach, we present Hunyuan Keyframe LoRA, an open-source solution built upon the Hunyuan Video framework. This model empowers creators to define keyframes and generate seamless video sequences, all within an open-source ecosystem
| Image 1 | Image 2 | Generated Video |
|---|---|---|
 |
 |
|
 |
 |
|
 |
 |
|
 |
 |
Architecture: Enhancing Keyframe Integration
Our architecture builds upon existing models, introducing key enhancements to optimize keyframe-based video generation:
- Input Patch Embedding Expansion: We modify the input patch embedding projection layer to effectively incorporate keyframe information. By adjusting the convolutional input parameters, we enable the model to process image inputs within the Diffusion Transformer (DiT) framework.
- LoRA Integration: We apply Low-Rank Adaptation (LoRA) across all linear layers and the convolutional input layer. This approach facilitates efficient fine-tuning by introducing low-rank matrices that approximate the weight updates, thereby preserving the base model's foundational capabilities while reducing the number of trainable parameters.
- Keyframe Conditioning: The model is conditioned on user-defined keyframes, allowing precise control over the generated video's start and end frames. This conditioning ensures that the generated content aligns seamlessly with the specified keyframes, enhancing the coherence and narrative flow of the video.
These architectural modifications collectively enhance the model's ability to generate high-quality videos that adhere closely to user-defined keyframes, all while maintaining computational efficiency.
Curating High-Quality Motion Sequences
A meticulously curated dataset is essential for training effective keyframe-based models. Our data collection strategy includes:
- OpenVideo1M Subset: We selected approximately 20,000 samples from OpenVideo1M, focusing on clips with high aesthetic value and dynamic motion.
- Dashtoon Internal Dataset: An additional 5,000 samples were incorporated from Dashtoon's proprietary dataset, primarily centered on human subjects.
- Data Filtering: Utilizing scripts from EasyAnimate, we filtered the dataset to exclude low-quality or repetitive frames, ensuring a diverse and high-quality training set.
Leveraging Keyframes for Seamless Transitions
Our training process is designed to fully leverage the power of keyframes, ensuring high-quality, temporally consistent video generation:
- Keyframe Sampling: We condition the model using static keyframes, specifically selecting the initial and final frames of videos as anchors for generation. To maintain consistency, we ensure that these keyframes do not contain significant motion, preventing unwanted artifacts in the generated sequence.
- Motion-Aware Sampling: During training, careful selection of keyframes is crucial—ensuring that the start and end frames are truly static helps establish a clear visual reference, allowing the model to infer smooth motion transitions more effectively.
- Temporal Consistency: The model is trained to generate intermediate frames that naturally bridge the defined keyframes, ensuring smooth, coherent transitions. By optimizing for temporal stability, the model maintains consistency in motion, structure, and subject appearance across the generated sequence.
These refinements enable Hunyuan Keyframe LoRA to produce high-quality, controlled video generations that align closely with user-defined keyframes while preserving natural motion dynamics.
During inference, Hunyuan Keyframe LoRA offers enhanced flexibility and control, enabling users to craft videos that align closely with their creative vision:
- Keyframe Specification: Users can define the initial and final frames, setting precise visual anchors that guide the video's narrative and flow.
- Variable Video Length: Trained on sequences of varying lengths, the model can generate between 33 to 121 frames between the specified keyframes, offering adaptability in video duration.
- Textual Prompts: While the model can operate without textual input, incorporating descriptive prompts significantly enriches the generated content's detail and relevance.
By combining keyframe control with flexible video lengths and optional textual guidance, Hunyuan Keyframe LoRA empowers creators to produce dynamic and tailored video content.
Conclusion
Hunyuan Keyframe LoRA democratizes keyframe-based video generation by offering an open-source alternative to proprietary models. We are fully open-sourcing the model weights, enabling the community to access, utilize, and build upon our work. Additionally, we are collaborating with the Hugging Face Diffusers library to integrate Hunyuan Keyframe LoRA, streamlining its adoption and fostering a more intuitive creative process. Future developments will focus on refining keyframe conditioning techniques, expanding dataset diversity, and enhancing user interfaces to make the creative process more seamless and accessible.
- Model weights are available on HuggingFace: [Control Lora]
- Training code is available on [Github]