Improving Control in Flux-Driven Image Generation

In our continuous effort to push the boundaries of controllable image generation, we've identified and addressed a critical gap in how current ControlNet models interact with the Flux pipeline. Despite the power of ControlNet, existing models — even when paired with Flux Ultra — fell short in several key areas such as structural accuracy, prompt fidelity, and response to control signals.
To address these constraints, we've developed a custom FluxDev fine-tune and a newly trained ControlNet variant that together produce markedly better results in structure-aware generation tasks like pose guidance, depth rendering, and edge detection conditioning.
🔍 The Challenge
While ControlNet-based models are generally effective at conditioning on structure-like inputs, we observed several limitations when applied within the Flux and Flux Ultra environments:
- Weak correlation between the input control maps and the generated features

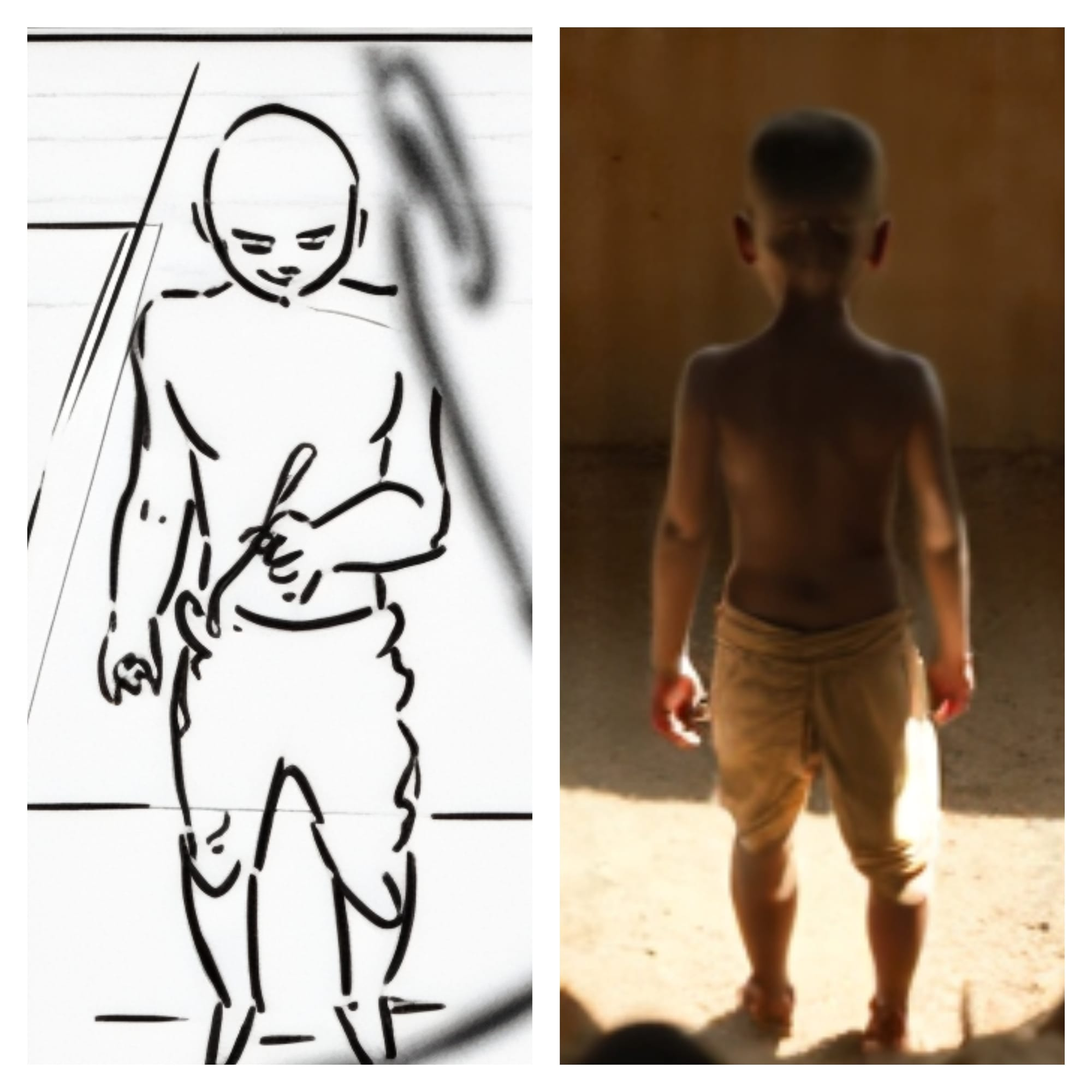
- Poor overall aesthetics in the outputs


📷 Sample Output — Existing ControlNet with Flux Ultra

🛠️ Our Solution
We initiated a comprehensive re-architecture of the Flux conditioning pipeline:
- Fine-tuned a FluxDev variant optimized for multi-stream attention flow
- Trained a custom ControlNet model on hybrid internal+public datasets across multiple conditioning maps (pose, depth, canny)
- Introduced dynamic control strength adaptation to maintain guidance integrity across a range of prompt lengths and noise thresholds
These updates significantly improve signal fidelity while still preserving generative flexibility.
📊 Performance Benchmarks
We evaluated our new control stack along three key dimensions: Control Adherence, Prompt Consistency, and Structural Error.
| Metric | Baseline (Existing ControlNet + Flux Ultra) | New Method (Custom FluxDev + ControlNet) |
|---|---|---|
| Control Map Adherence (SSIM) | 0.68 | 0.84 |
| Prompt/Control Harmony (%) | 71% | 92% |
| Structural Deviation (low = better) | 0.342 | 0.112 |
| Artifact Rate (per 100 imgs) | 18.2 | 4.7 |
Additionally, average inference latency stayed within ±5% compared to the previous method, indicating no significant trade-offs in speed.
🧠 Architecture Notes
Below is a high-level overview of what has changed in the architecture layout:
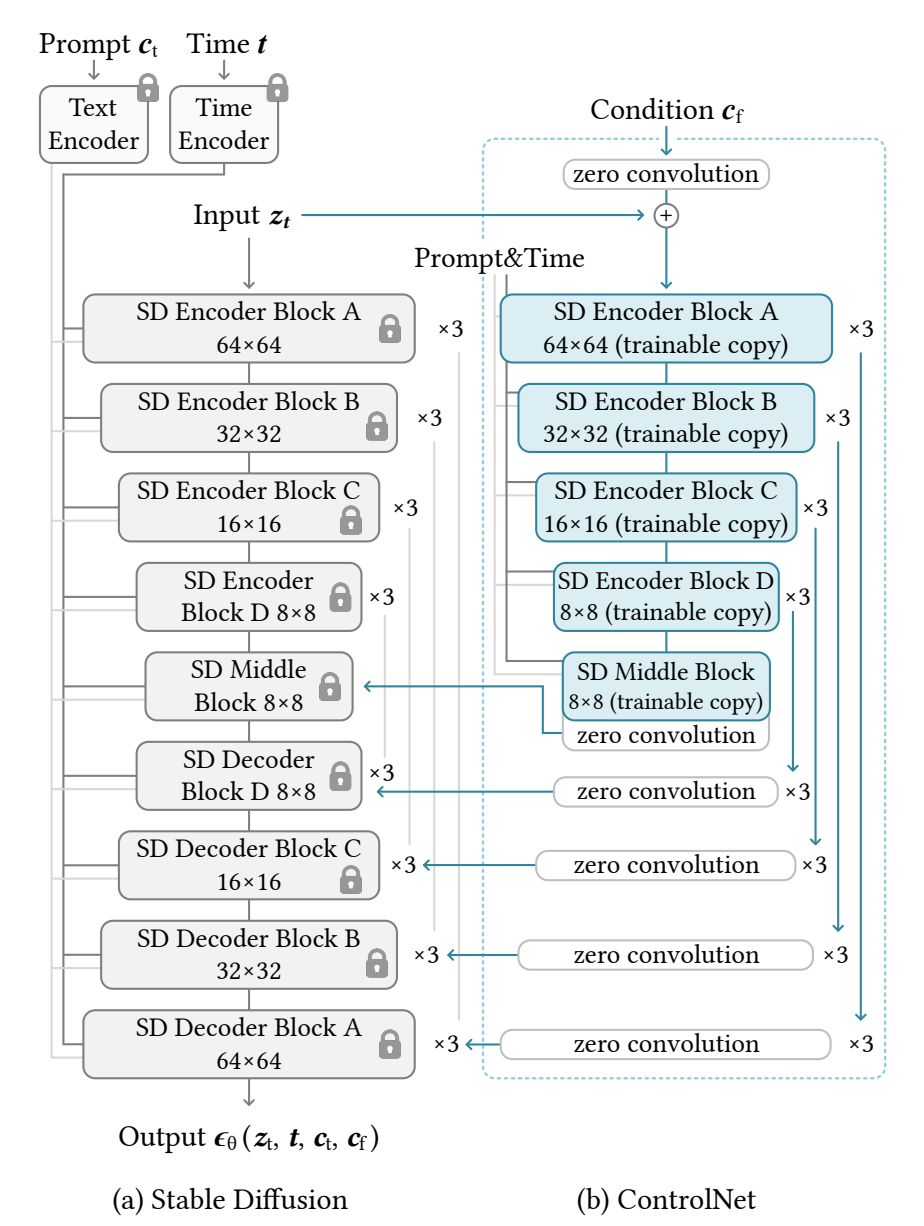
- ControlNet Input Pathway:
- Swapped out standard adapter layers for multi-head attention fusion blocks
- Introduced gated skip connections from early encoder positions for stronger pose retention
- Training Setup
- Dataset: 1.3M control-labeled image pairs (pose, depth, etc.)
- Target losses: MSE for control adherence, perceptual loss for image fidelity
➕ What’s Next
We’re continuing to iterate on other control domains, including semantic maps and sketch-based prompts, using similar architectural principles. Additionally, we’re exploring interpolation guidance — where users can blend between multiple control signals dynamically during generation.
However, one issue we’ve observed with this model is that generations often adopt an overly blueish color tone.


This unintended color bias reduces the naturalness of outputs and makes them appear more stylized than realistic. The effect is especially noticeable on skin tones, clothing, and ambient lighting, where cooler hues dominate regardless of the intended palette.
We suspect a few possible causes for this issue:
- Training data imbalance – if a significant portion of the dataset contains cooler/blue-tinted lighting conditions, the model may overfit to that distribution.
- Conditioning signal leakage – certain control modalities (e.g., depth maps or sketch prompts) might bias the network toward cooler tones due to how they were preprocessed or normalized.
- Interpolation interactions – blending multiple control signals dynamically may amplify subtle biases, leading to a systematic shift toward blueish palettes.
Addressing this requires better color consistency handling within the control framework to ensure that user-specified prompts and reference conditions are respected without introducing systematic tinting artifacts.