Insights from Our Adversarial Diffusion Distillation POC

When building a comic creation platform, speed and efficiency are paramount. Users expect rapid feedback, especially when generating images through multiple iterations. To meet this demand, we turned to Adversarial Diffusion Distillation, a cutting-edge technique designed to speed up image generation without sacrificing quality. In this blog post, we'll share why we chose this approach, how we implemented it using our own in-house models, and the steps we took to streamline our process.
Why Adversarial Diffusion Distillation?
- Faster Inference Speed: Reducing the time it takes to generate images improves the user experience. The faster we can deliver outputs, the more seamless the creative process becomes for our users. Additionally, quicker generation times reduce operational costs for us, ensuring a more sustainable business model.
- Efficient Iteration in Comic Creation: Comic creation is an iterative process. Artists frequently modify images before reaching their final version. Showing image outputs quickly allows creators to make adjustments on the fly, fostering a smoother creative workflow.
Introduction
The goal is to generate high-fidelity samples quickly while achieving the quality of top-tier models. The adversarial objective enables fast generation by producing samples in a single step, but scaling GANs to large datasets has shown the importance of not solely relying on the discriminator. Incorporating a pretrained classifier or CLIP network enhances text alignment, however, overuse of discriminative networks can lead to artifacts and reduced image quality.
To address this, the authors leverage the gradient of a pretrained diffusion model through score distillation to improve text alignment and sample quality. The model is initialized with pretrained diffusion model weights, known to enhance training with adversarial loss. Finally, rather than a decoder-only architecture typical in GAN training, a standard diffusion model framework is adapted, allowing for iterative refinement.
Training Procedure
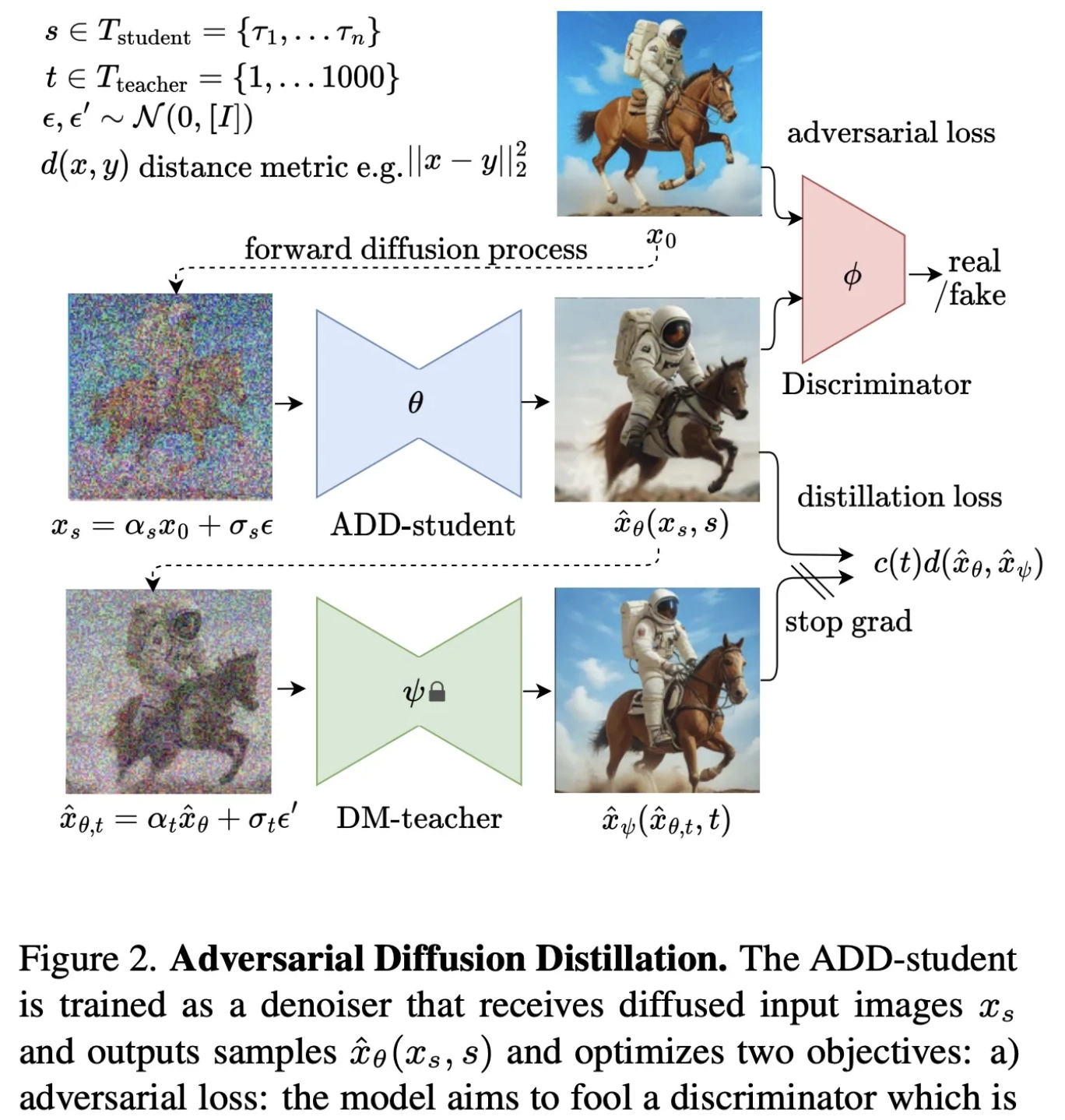
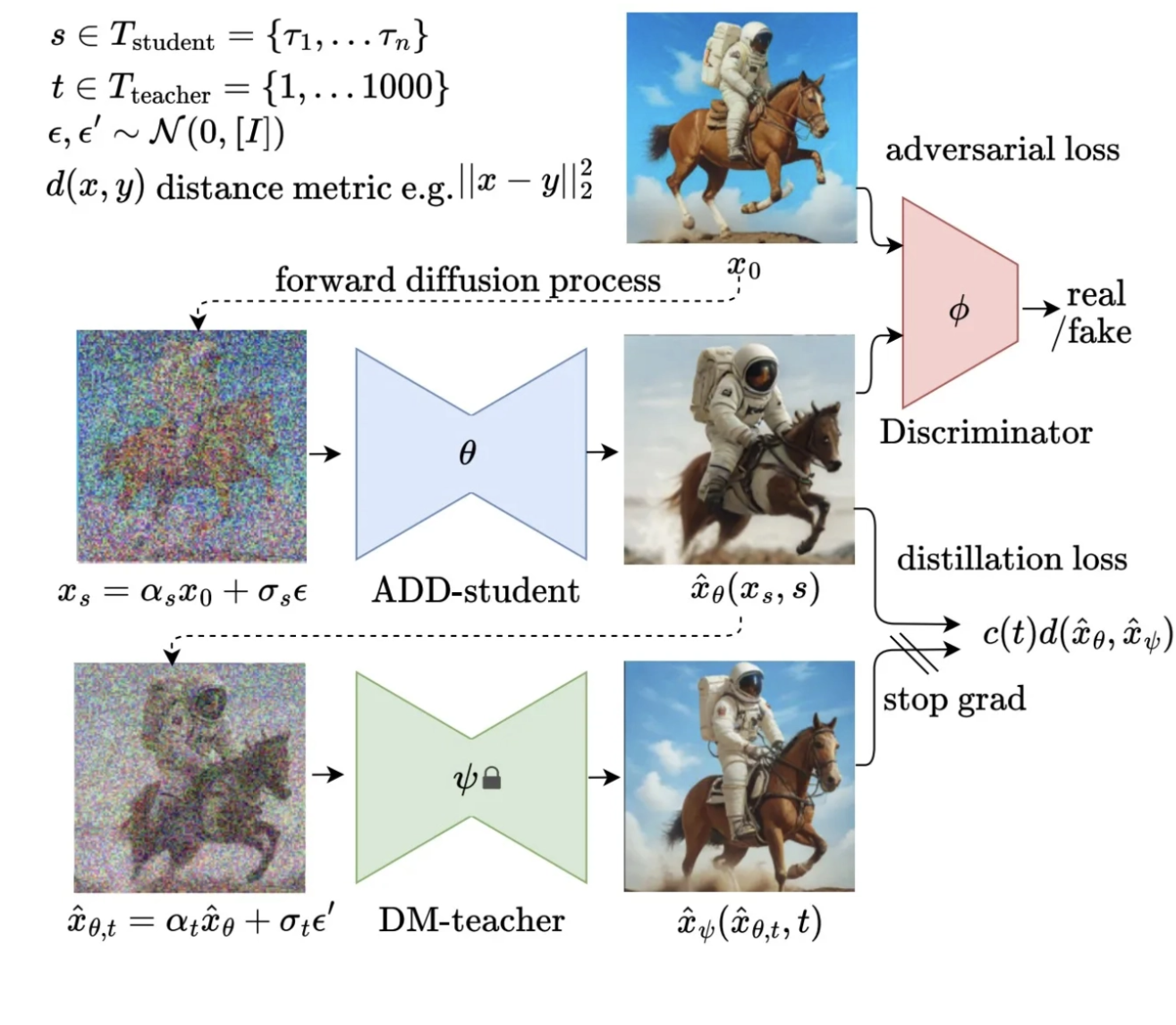
The training procedure involves three networks: the ADD-student initialized from a pretrained UNet-DM, a discriminator with trainable weights, and a DM teacher with frozen weights. The ADD-student generates samples from noisy data, which are produced from real images through a forward diffusion process. The process uses coefficients and samples timesteps uniformly from a chosen set, typically four timesteps, starting from pure noise.
For the adversarial objective, the discriminator distinguishes between generated samples and real images. Knowledge is distilled from the DM teacher by diffusing student samples with the teacher’s process and using the teacher’s denoising prediction as a reconstruction target for the distillation loss. The overall objective combines the adversarial loss and distillation loss.
The method is formulated in pixel space but can be adapted to Latent Diffusion Models operating in latent space. For LDMs with a shared latent space between teacher and student, the distillation loss can be computed in either pixel or latent space, with pixel space providing more stable gradients for distilling latent diffusion models.
Adversarial Loss
The discriminator design and training procedure use a frozen pretrained feature network, typically ViTs, and a set of trainable lightweight discriminator heads applied to features at different layers of the network. The discriminator can be conditioned on additional information, such as text embeddings in text-to-image settings, or on a given image, especially useful when the ADD-student receives some signal from the input image. In practice, an additional feature network extracts an image embedding to condition the discriminator, enhancing the ADD-student’s use of input effectively. The hinge loss is used as the adversarial objective function.
Score Distillation Loss
The distillation loss measures the mismatch between samples generated by the ADD-student and the outputs from the DM-teacher, using a distance metric. The teacher model is applied to diffused outputs of the student’s generations, not directly to the non-diffused student outputs, as these would be out-of-distribution for the teacher.
The distance function used is the squared L2 norm. The weighting function has two options: exponential weighting, where higher noise levels contribute less, and score distillation sampling weighting.
Dashtoon’s Experiments
We began by carefully studying the key details from the original Adversarial Diffusion Distillation paper. The goal was to transfer knowledge from a larger, pre-trained model (the teacher) to a smaller, more efficient model (the student), all while maintaining the quality of generated images.
For our implementation, we selected diffusers, a flexible and efficient framework for diffusion models. Below, we walk through the main components of our training process.
- Teacher Model: We used our in-house trained SDXL model, which we call dashanime-xl. This model has been fine-tuned on a wide array of anime images, ensuring that it understands the nuances of comic-style art.
- Student Model: The student model was initialized from the pretrained weights of dashanime-xl. Starting from a strong base model allowed us to train faster while preserving image quality.
- Discriminator: We used a discriminator, just as described in the paper. The discriminator includes two key components:
- Text Embeddings: Generated from a pretrained CLIP-ViT-g-14 text encoder, which helps evaluate how well the generated image aligns with the text prompt.
- Image Embeddings: Extracted using the CLS embedding of a DINOv2 ViT-L encoder. This ensures that the images generated by the student model maintain high fidelity and visual quality.
- Training Dataset: Our training dataset consists of 2 million publicly available anime images, curated and filtered using the process we detailed in our blog post about dashanime-xl. This dataset was essential in ensuring that our models learned to generate high-quality anime-style artwork.
Below is the pseudo code outlining our training process using diffusers:
- Compute student predictions
- Compute the teacher predictions on student predicted x0
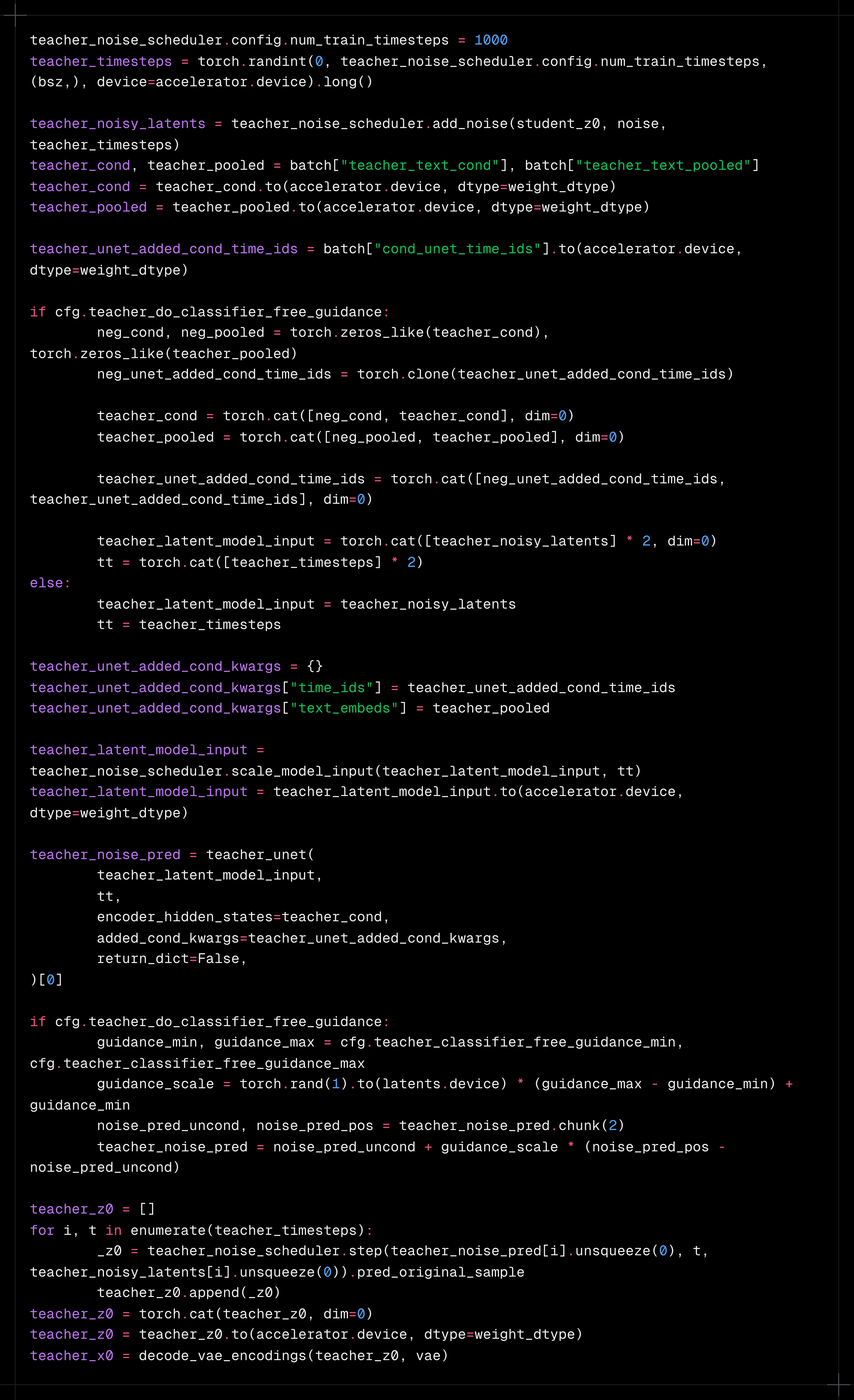
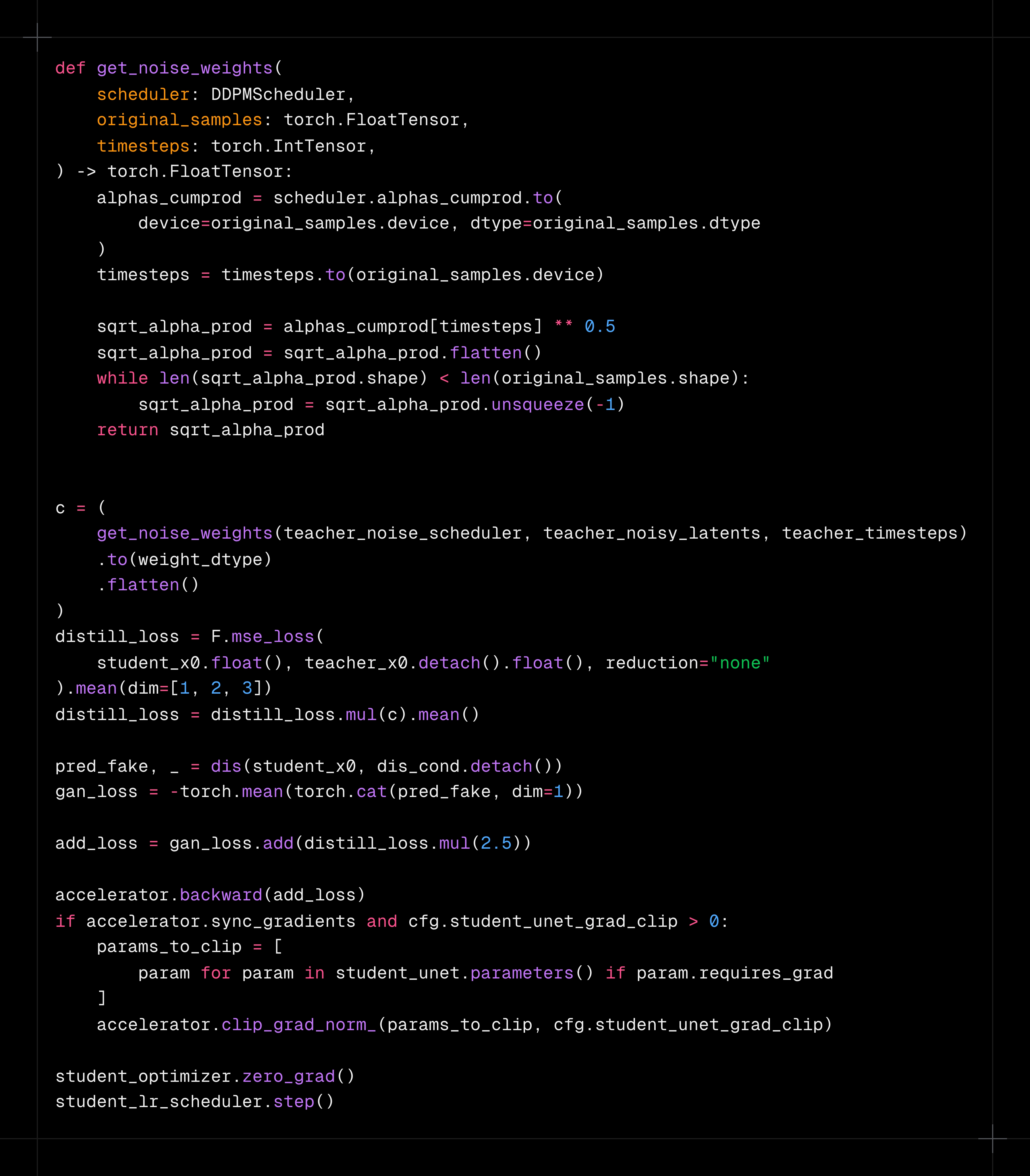
- Computing the GAN loss

- Compute the distillation loss. We used the exponential weighting scheme for the score distillation loss
Experiment Results
By applying Adversarial Diffusion Distillation, we successfully reduced inference times while maintaining the high-quality outputs that are essential for comic creation. The student model now generates images significantly faster than the teacher model, providing creators with a smoother and more efficient experience.

Due to time constraints, we weren't able to perform a thorough quantitative evaluation of our new model, but we did manage to test it qualitatively. We're excited to share some of the results generated by our dashanime-xl-1.0-turbo, the outcome of our Adversarial Diffusion Distillation (ADD) implementation.
Our initial tests show that dashanime-xl-1.0-turbo performs impressively, producing high-quality anime-style images with significantly reduced generation times. The faster inference speed makes it ideal for rapid iteration during the comic creation process, fulfilling our goal of delivering seamless user experiences.
While we still plan to conduct comprehensive quantitative tests, these initial qualitative outputs are promising. They highlight dashanime-xl-1.0-turbo's ability to generate intricate and stylistically consistent images rapidly. The model's ability to maintain image quality while reducing generation time is a significant leap for use cases like comic creation, where speed and creative flexibility are crucial. Our next steps include further fine-tuning and testing on a broader range of comic styles and scenarios. We’re also exploring ways to integrate this approach directly into our platform to allow for real-time image generation.
Stay tuned as we refine the model further and move on to more quantitative analysis to showcase the full potential of dashanime-xl-1.0-turbo!
In this blog post, we've highlighted the technical aspects of implementing Adversarial Diffusion Distillation, but the implications for user experience and efficiency are even more exciting. As we roll out these enhancements, we’re eager to see how our community of creators utilizes this newfound speed and power in their projects.