Introducing DashAnime XL 1.0


Dashtoon Studio is an innovative AI-powered platform designed to empower creators in the art of comic crafting. The immense popularity and profound cultural influence of anime have sparked a fervent demand from our user base for this distinctive style. Recognizing this enthusiasm, we embarked on an ambitious journey to develop a state-of-the-art anime image generation model specifically tailored for storytelling. Our goal was to create a tool that not only meets the high expectations of anime enthusiasts but also enhances the creative process for comic artists working in this beloved medium.
The Art of Anime: Dashtoon's Need for a Dedicated Model
Existing anime models primarily rely on danbooru tags, which can make it challenging for a novice user to control these models effectively. Additionally, these models often exhibit low prompt adherence. With these challenges in mind, we set out to create an anime model that responds accurately to natural language prompts. To achieve this, we used SDXL as our base architecture.
Dataset Curation & Captioning
We trained our model using a carefully curated dataset of approximately 7 million openly avaialble anime-styled images. In projects like this, a common technique is to recaption all images to eliminate any faulty text conditions in the dataset. To achieve this, we employed our in-house Vision Large Language Model (VLLM) for captioning, which significantly enhances the model's ability to follow instructions accurately. This step was crucial to ensure the model's effectiveness with natural language, as the existing captions for anime-style images are predominantly in the Danbooru style, which we aimed to avoid.
Danbooru-style prompting involves guiding the model using tags found on the danbooru. This approach can be particularly challenging for novices, as danbooru contains a vast number of tags. Achieving the desired generations often requires experimenting with multiple tags and demands extensive knowledge of the available tags.
Balancing the dataset …
The anime dataset we curated (also any anime based dataset in general) exhibits a significant long-tail distribution phenomenon, where some less common concepts have fewer samples due to their niche nature or recent introduction. While many of these concepts are quite interesting, direct training often makes it difficult for the model to learn them effectively.
Below are some examples illustrating how this long-tail distribution impacts the final image generation. Even if we don't explicitly tag an image to include a girl, the model might inadvertently generate one, which is an outcome we want to avoid. The images shown below are generated using an open-source anime model, we also add images generated by DashAnimeXL for comparison.
| Prompt | Generated Image | DashAnimeXL |
|---|---|---|
| a wall |

|

|
| abstract shapes and colours |

|

|
| a horse |

|

|
| a book |

|

|
| a tree |

|

|
| A vibrant street mural covering an entire wall |

|

|
We implemented specific balancing strategies to smooth out the original data distribution:
- We partitioned the dataset into specific tag groups based on our internal testing and analysis
- We then sampled tags within the selected categories separately. To balance the dataset, we reduced the influence of tags from high-frequency categories and increased the sampling frequency of tags from low-frequency categories. Using these adjusted sampling frequencies, we reconstructed the dataset, resulting in a smoother distribution across the categories.
- Finally, all the images were captioned in natural language using our in-house captioning tool.
We primarily categorised the entire dataset into one of the buckets (the actual list of buckets is exhaustive and here we provide only the most important ones):
- 1 girl with emotion: Includes images where a girl showing any emotion is the central figure.
- 1 girl only: Includes images where a girl is the central figure
- 1 boy with emotion: Includes images where a boy showing any emotion is the central figure.
- 1 boy only:Includes images where a boy is the central figure
- multiple girls: Includes images with multiple girl characters
- multiple boys: Includes images with multiple boy characters
- animal: Includes images where an animal is the central figure
- object: Includes images where an object is the central figure
- is_no_human: Includes images with no human subjects, focusing on scenery or backgrounds.
After categorising the data, we ensured that each image was assigned to exactly one bucket. This step was crucial to avoid inadvertently skewing the weight of any particular category. Once the images were correctly categorised, we adjusted the weightage of each bucket. Specifically, we increased the weight of underrepresented buckets and decreased the weight of overrepresented ones, aiming to balance the distribution and bring each bucket's weight closer to the median of the overall dataset.
The pseudo-code looks something like this :
# Step 1: Analyze and categorize tags
for each tag in Danbooru dataset:
assign tag to appropriate category based on its characteristics
# Step 2: Separate and sample tags within each category
for each category in dataset:
calculate frequency of each tag in the category
if category is high-frequency:
reduce sampling frequency
else if category is low-frequency:
increase sampling frequency
# Step 3: Reconstruct dataset with balanced sampling
balanced_dataset = []
for each category in dataset:
sampled_tags = sample_tags(category, adjusted_sampling_frequency)
add sampled_tags to balanced_dataset
# Step 4: Categorize images into buckets
for each image in balanced_dataset:
assign image to one of the buckets:
- 1 girl with emotion
- 1 girl only
- 1 boy with emotion
- 1 boy only
- multiple girls
- multiple boys
- animal
- object
- is_no_human
# Step 5: Ensure each image is in exactly one bucket
for each image in balanced_dataset:
if image is assigned to multiple buckets:
remove from all but one bucket
# Step 6: Adjust bucket weights to balance distribution
for each bucket in balanced_dataset:
if bucket is overrepresented:
decrease weight
else if bucket is underrepresented:
increase weight
# Step 7: Final dataset preparation
final_dataset = apply_weighting(balanced_dataset)
caption_images(final_dataset, captioning_tool)
From long captions to short captions …
In our initial experiments, we began with very long and descriptive prompts, which significantly enhanced the model's ability to follow instructions. However, we soon observed a decline in performance when using shorter prompts. This approach also introduced style inconsistencies, as some image captions included style references while others did not. This inconsistency occasionally led the model to generate realistic images when we actually desired a different style. Style inconsistency is a significant concern for us because we are engaged in storytelling through comics. Visual continuity needs to be maintained from panel to panel and across hundreds of chapters. Maintaining a consistent visual style is crucial for ensuring that our readers remain immersed in the story without distractions.
Upon further investigation, we traced this issue back to inherent biases in the SDXL and inconsistent captioning of training dataset.
Below, we present some examples of model generations that exhibit style inconsistencies. In these cases, we intended to produce images in an anime style, but instead received realistic images.




Below we present some examples that highlight labelling inconsistencies within the dataset. Notice how certain samples explicitly include the "anime" style in the caption, while others do not. This inconsistency leads the models to develop their own biases, resulting in unpredictable behaviour during inference. Specifically, we observed that the output image styles became inconsistent—sometimes appearing in an anime style and other times in the default SDXL realistic style as shown above. For instance, some captions include phrases like animated characters and A stylized, illustrated. Additionally, in our full dataset, we discovered that many images contain keywords such as A digital illustration, A cartoon-style illustration, and A stylized, anime-style character.
| Image | Caption |
|---|---|

|
Two animated characters, one with brown hair and one with green hair, both wearing black and red outfits with accessories. The character on the left holds a vintage-style camera, while the character on the right holds a smartphone. They stand in front of a plain background with a red object visible to the right. The characters have a friendly demeanor, with the brown-haired character smiling and the green-haired character looking at the camera with a slight smile. |

|
A girl character with long, light-colored hair, large blue eyes, and a black and white outfit with a bow tie. She is smiling and appears to be in a cheerful mood. The character is positioned in the foreground against a white background with scattered orange and pink hues. |

|
An illustration of a man with spiky, dark blue hair and striking red eyes. He is wearing a black and white checkered shirt and a black choker. His right hand is raised to his chin, with his index finger resting on his cheek, while his thumb is tucked under his chin. He is holding a white electric guitar with a brown pickguard and six strings. The background is minimalistic, featuring a white wall with a red and white sign partially visible. The style of the image is cartoonish, with a focus on the character's expressive features and the guitar, suggesting a theme of music and youth culture. |

|
A girl riding a tricycle. She is depicted from the back, wearing a black and white outfit with a hoodie, leggings, and sneakers. Her hair is styled in a bun with two pigtails on top. The background is a solid red color. The girl is positioned on the right side of the image, with her left foot on the front wheel and her right foot on the back wheel. |

|
A stylized, illustrated character with angelic features, standing centrally with arms outstretched. The character has large, feathered wings with a gradient of blue and white, and is adorned with a golden, ornate armor-like outfit with circular designs on the chest and arms. The character's hair is short and dark, and they have a serene expression. Behind the character is a symmetrical, stained-glass window-like background with intricate patterns and motifs, including a central circular emblem with a face, surrounded by four smaller circles with various symbols. The background is a blend of pastel colors, predominantly in shades of blue, white, and peach. There is no text present in the image. The lighting appears to be emanating from the central emblem, casting a soft glow on the character and the surrounding patterns. The style of the image is a digital illustration with a fantasy or mythical theme. The character appears to be a girl, and the overall mood conveyed is one of tranquility and ethereal beauty. |

|
A male character with spiky blond hair and blue eyes, wearing a green military-style jacket with gold buttons and a white shirt. He holds a sword with a golden hilt and a silver blade, examining it closely. The character's expression is focused and serious. |
To address this, we developed an in-house LLM that compresses these ultra-descriptive captions into short, concise ones, deliberately omitting any style references. In later experiments, we discovered that adding "anime illustration" as a prefix significantly improved the quality of the generated images. As a result, we applied this prefix to all captions in our training dataset.
| Image | Caption |
|---|---|

|
Long Caption: An animated character with green hair and green eyes, wearing a blue and white outfit with a high ponytail. she is holding a sword with both hands, and the sword is emitting a bright light, suggesting it might be a magical or special weapon. the character is looking directly at the viewer with a focused expression. she is wearing fingerless gloves and has a rope belt around her waist. the background is a warm, brownish color, which could indicate an indoor setting or a warm environment. the character's attire and the style of the image suggest it is related to the fire emblem series, specifically referencing the game fire emblem: the blazing blade and the character lyn from that game. the image is rich in detail and conveys a sense of action and readiness. Short Caption: A girl with long, dark green hair and striking green eyes. she is adorned in a blue dress with intricate designs and accessories, including earrings and a belt with a pouch. She is holding a sword, which emanates a glowing blue light, suggesting it might be enchanted or imbued with some magical power. |

|
Long Caption: An animated character from the "the idolmaster" franchise, specifically from Short Caption: A girl character with long, vibrant blue hair and striking blue eyes. she's adorned in a black dress with intricate lace and frill details, complemented by black gloves and knee-high boots. the character holds a black umbrella with a decorative ribbon, and her gaze is directed towards the viewer. the background is a muted grey and the character has a few tattoos on her arm. |
Adding special tags for improved control …
In addition to recaptioning the entire dataset, we retained a select few tags that we identified as crucial for enhancing the model's learning capabilities.
We carefully curated a list of special tags from the original Danbooru prompts, recognizing that certain tags, such as lowres, highres, and absurdres, were essential for guiding the model toward better generations. We also preserved the character name and series name tags from the original danbooru prompts.
Furthermore, we introduced special tags to each image in the dataset to provide more control over the model's output. These tags serve specific purposes:
- nsfw rating tags: safe, sensitive, general, explicit, nsfw
- aesthetic tags: very aesthetic, aesthetic, displeasing, very displeasing
- quality tags: masterpiece quality, best quality, high quality, medium quality, normal quality, low quality, worst quality
Assembling the final prompts
Using the above guidelines, we arrive at the final assembled prompt structure:
anime illustration, [[super descriptive prompt OR condensed prompt]]. [[quality tags]], [[aesthetic tags]], [[nsfw rating tags]]
This final prompt structure ensures that each generated image aligns with the desired style, quality, and content, providing a comprehensive framework for creating high-quality anime illustrations.
Our model leverages special tags to guide the output towards specific qualities, ratings, and aesthetics. While the model can generate images without these tags, including them often results in superior outcomes
Below we showcase some examples from our training dataset after assembling the final prompt.



Training details
This model architecture is built on the SDXL model. After performing rule-based cleaning and balancing on the dataset (as discussed above), we fine-tuned the model over a total of 25 epochs following this schedule:
- Epochs 1-10:
- We fine-tuned both the Unet and CLIP Text Encoders to help the model learn anime concepts.
- During this stage, we alternated between using super descriptive captions and short captions in the training process.
- While this approach improved the model's understanding of anime concepts, it also introduced the style inconsistency issue described earlier. We decided to retain the text encoders and the unet from this stage, add "anime illustration" to all the training data, and remove all style references from the images in stage 2.
- The sample size during this phase was approximately ~5M images.
- Epochs 10-25:
- We shifted focus to fine-tuning only the Unet from stage 1, aiming to refine the model's art style and improve the rendering of hands and anatomy.
- In this stage, we trained exclusively on short captions.
- The dataset was further filtered down to ~1.5M images.
Both stages of training employed aspect ratio bucketing to prevent the degradation of image quality in the training samples.
Throughout both stages, we used the Adafactor optimizer, which we found to offer the best memory/performance ratio. Initially, we experimented with kohya's sd-scripts for the training but soon developed our own tooling around diffusers, mosaicml-streaming, and pytorch-lightning to handle the massive data loads and scale efficiently across multiple nodes.
mosaicml-streaming in particular played a crucial role in meeting our dataset requirements by enabling seamless scaling across multiple nodes. It provided an optimal balance, allowing us to stream large amounts of data in and out of multiple nodes while leveraging local NVMe space as a staging ground.
Evaluation
We experimented with nearly all of the open-source benchmarks for diffusion models, including DPG and Geneval. However, we quickly realised that these existing benchmarks don't account for the specific factors that are crucial in show and comic creation. In comic creation, aspects such as character consistency, multi-character interaction, scene interaction, and overall consistency are more important.
Drawing insights from the existing benchmarks, particularly the excellent DPG benchmark developed by the ELLA team, we developed our own benchmarks tailored specifically for show and comic creation. A more detailed blog on this topic will be released in the future. With these considerations in mind, we present our benchmark scores.
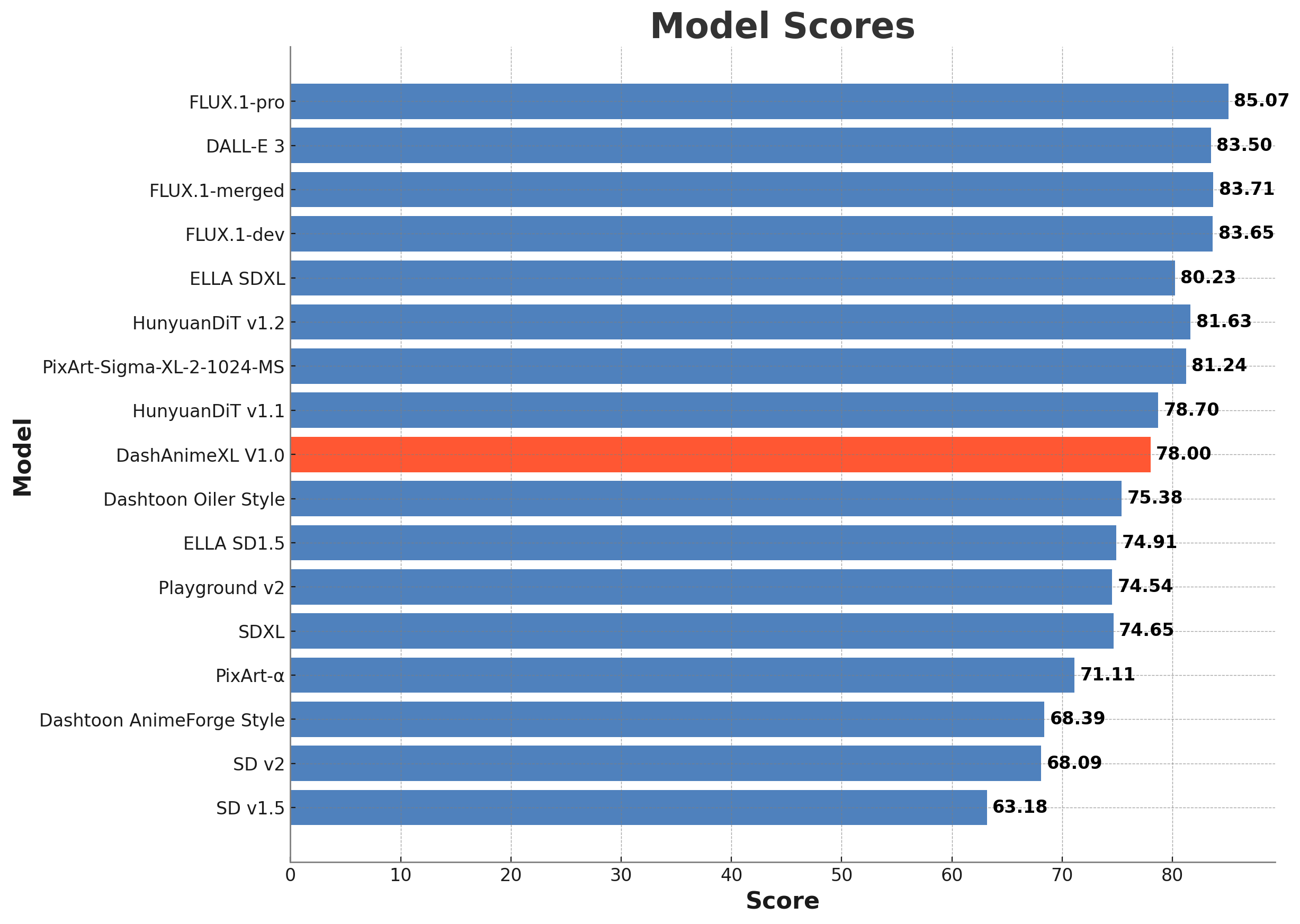
From our internal testing metric, we concluded that our model demonstrates superior prompt adherence compared to other anime models available in the market. One of the key advantages of our model is its ease of use—there's no need to rely on danbooru tags to generate high-quality images. Instead, this can be easily achieved through natural language prompting.
We plan to conduct a more comprehensive study in the future to further validate and refine our model's capabilities. While our model performs well overall, we aim to further enhance its capabilities by incorporating more detailed character and style information. Currently, the model struggles to consistently generate styles beyond the base anime style. We plan to address this in future iterations, ensuring more consistent and diverse stylistic outputs.
Results Showcase




























How to use
DashAnimeXL is now publicly available on the Dashtoon Studio ! Head over there to check it out. Refer to the video below for a guide on how to use it.
The model is also available in Huggingface and Civitai
What’s next ?
Recently, we've seen the FLUX gaining traction, and our internal benchmarks also found FLUX to be very promising for show and comic creation.
However, we observed a significant issue with style inconsistency, especially when deviating from the realistic style. The anime style, in particular, tends to be quite inconsistent.
As a way to contribute to the open-source community, we plan to release some cool variants of FLUX in the coming weeks.
Here’s a sneak peek at some of the upcoming outputs.
.png)