A Road Towards Tuning-Free Identity-Consistent Character Inpainting
At Dashtoon, we are dedicated to simplifying and enabling seamless visual storytelling through comic creation, with character creation at the heart of this process. Our mission is to make storytelling accessible to everyone by empowering users to craft personalized characters—whether entirely original or inspired by real-world personas—that bring their narratives to life. Comics, by nature, involve creating multi-panel, multi-page stories, where maintaining consistency in character design is essential. Ensuring that characters retain their intrinsic attributes—such as facial features, hairstyles, body shapes, and other physical traits—across diverse scenes and frames is critical to achieving narrative coherence and visual continuity (Fig A and B). This focus on character consistency underpins the immersive storytelling experience we aim to deliver, offering users the flexibility to shape narratives that reflect their ideas, identities, and imagination.


To support this, we are working to adapt Text-to-Image generative models for efficient and scalable ID-driven synthesis, which is formally defined in the next section.
1 | ID-Consistent Synthesis—What is it?
It’s a direction within the field of text-to-image generation aimed at creating visually coherent images that maintain a subject's identity (ID) across varied prompts defining diverse situations or artistic variations. Unlike traditional generative models that focus on general styles or objects, ID-consistent synthesis deals with a relatively subtle task of preserving intricate identity details—such as facial features—of a person or object from a single or limited reference image. Recent advances in diffusion models like Stable Diffusion [19], DALL-E3 [18], and Flux [15] have significantly improved creative, context-rich image generation. However, ensuring identity consistency remains challenging, as these models balance preserving identity with aligning to diverse prompts.
1.1 | The Spectrum of Methods
The problem can fundamentally be addressed through three distinct dimensions, each defined by the role of model training:
- Test-time optimization methods, exemplified by techniques like DreamBooth [10] and Textual Inversion [11], rely on fine-tuning the model specifically for each subject or object. These methods are both time-consuming and computationally demanding as they require per-subject optimization and often multiple reference images, which limit their scalability in practical applications.
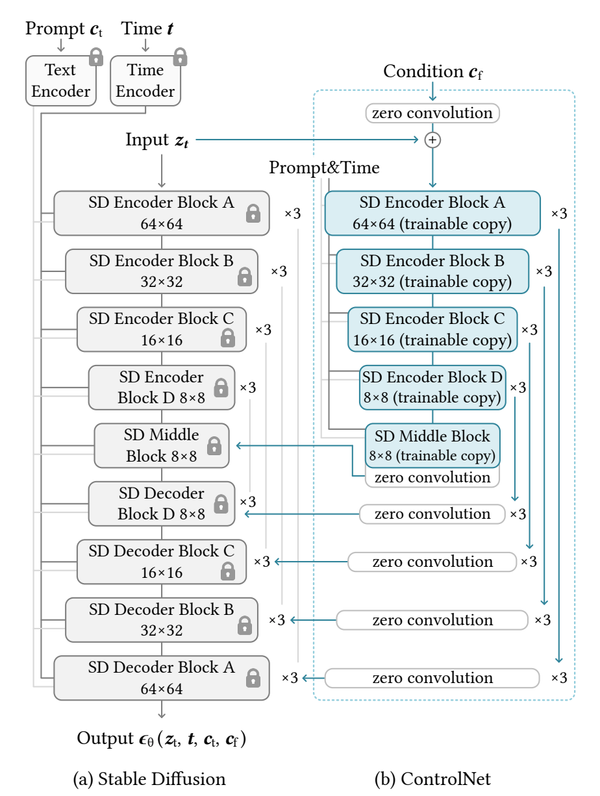
- Tuning-free methods. The focus of these is to tune specialized ID adapters that inject identity information into the base generative model. Approaches like InstantID [2] and PULID [13] leverage these adapters or conditioning strategies to generate consistent images for unseen subjects, avoiding per-subject optimization.
- Training-free approaches eliminate the need for any training. These methods focus on inference-time manipulations to achieve identity consistency, primarily by adjusting attention layers across batches to align with the reference identity. We will touch on this briefly at the end of our article.
Among these approaches, the focus of this article lies on the second dimension—tuning-free methods—and the advancements we have contributed in this space.
Let’s begin with how we constructed our data pipeline to facilitate extraction of consistent character images for model training.
2 | Dataset Construction Flow
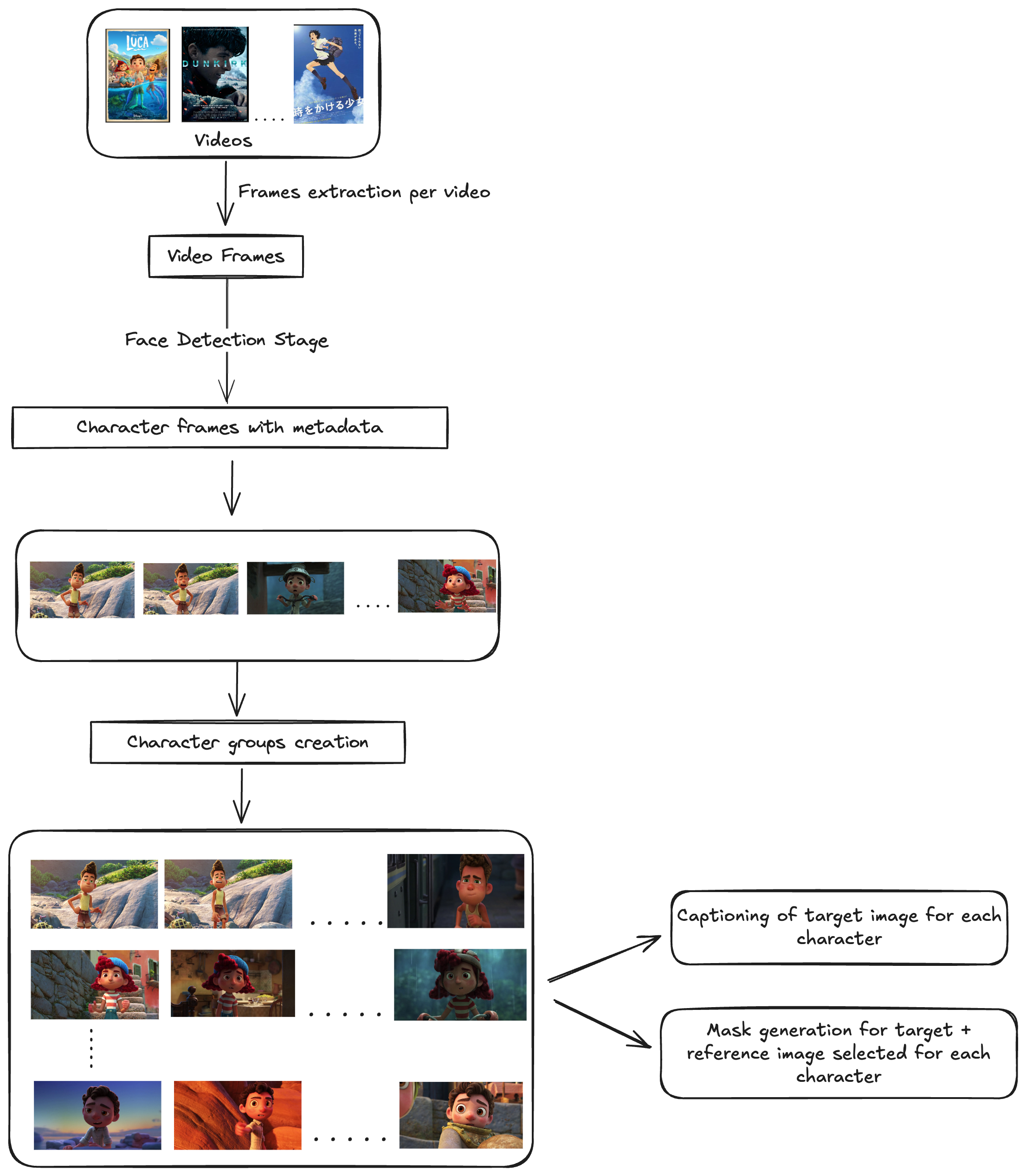
Curating datasets for consistent character generation presents specific challenges due to the inherent requirement for structured data in the form of triplets. These triplets consist of: (1) a reference or ID image that defines the subject to remain consistent across generations, (2) a text prompt describing how the subject should appear in the generated image, and (3) a target image showcasing the subject as specified by the text prompt.
To meet our dataset requirements, we opted for a large-scale collection of movies. Movies offer a valuable resource, as they consist of numerous image frames featuring various characters across different scenes. By leveraging appropriate deep learning approaches, we can efficiently extract multiple consistent images of distinct characters from a single movie, providing a rich source of structured data for our needs.
Furthermore, our goal was to train the model using in-the-wild reference images, ensuring that user-provided reference images are not limited to portrait, front-facing, or close-up formats. Character images extracted from movie frames satisfied this requirement for the dataset.
2.1 | Character aggregation phase
Below are details for the dataset construction pipeline:
- Frame extraction: For each movie, frames were extracted using a frame skip value of 50, chosen as an optimal balance based on empirical observations. A lower value yielded redundant frames with minimal variation, while a higher value risked missing sufficient consistent and diverse frames for character representation. In total, frames were extracted from over 1200 movies scraped from the web.
- Face detection stage: We use the ArcFace [3] module to detect human faces in the frames extracted from the movie. Frames with no detected faces are discarded. For frames where multiple faces are detected, we calculate the pairwise cosine similarity of the face embeddings and sum these similarities for each detected face. The face with the lowest cumulative similarity score is selected, as it is deemed to be the most unique or distinctive among the detected faces. This ensures consistency in selecting a single representative face per frame, even when multiple faces are present. The selected face's embedding, bounding box, keypoints, and corresponding frame information are stored for further processing.
- Grouping distinct characters: After extracting the face embeddings and their associated metadata from the frames, we group the frames into clusters based on cosine similarity of the embeddings. This process is carried out using a similarity threshold to identify frames that likely belong to the same character. Frames are iteratively compared, and those with a similarity score above the defined threshold are grouped together. Each group represents a distinct character, with its frames ordered by descending similarity scores.Once the groups are formed, we apply additional filtering criteria to ensure the quality and usability of the groups. Groups with fewer than the minimum required frames are discarded, while a maximum number of frames is retained for groups exceeding the limit. The final output is a set of structured character data, where each distinct character is represented by its frame IDs, bounding boxes, and facial landmarks.
With this, we extracted around 50k IDs from the movies.

2.2 | Mask Generation
For the consistent frames aggregated in the previous step, we generate segmentation masks for the target character using the SAM (Segment Anything Model) [7]. Since each frame may contain multiple faces or human figures, the face bounding box stored for each frame is uniquely associated with the target character. To generate masks, we utilize the midpoint of the face bounding box as the input to the segmentation model. For each input frame, the model produces a multi-mask output, from which we select the mask with the largest area.
Note 1: The quality of the generated masks can be further enhanced by incorporating whole-body bounding boxes. This is achieved by using Grounding-DINO or other object detectors to detect all bounding boxes for humans within the frame. The bounding box with the largest overlap with the target face bounding box is then used as the input to the segmentation model, providing a more accurate and refined segmentation of the target character.
Note 2: Specialized segmentation models can be employed for anime images, as general-purpose models such as SAM often exhibit suboptimal mask quality in certain cases.
Fig 2.0 and 2.1: Extracted frames for a character with its corresponding segmentation masks


More Samples



2.3 | Captioning
In this study, we used InternVL2-26B [6] as the Vision-Language Model (VLM) to generate high-quality captions tailored to our needs, providing descriptive textual annotations for target images.
To ensure precision and relevance, we developed a structured instruction prompt template to guide the VLM in producing focused descriptions. The prompt emphasized key aspects such as appearance, clothing, expressions, gestures, and interactions while excluding irrelevant details. Constraints on word count (100–150 words) and avoidance of subjective or speculative details further refined the output, ensuring captions aligned with the inpainting task's requirements.
The prompt template, shown below, helped meet our training objectives.
Prompt Template:
Describe the image in detail, STRICTLY keeping it under 100-150 words, in a single coherent paragraph.
DO NOT BEGIN WITH 'This image shows', 'In this image', 'The image depicts', etc. Clearly specify the gender (man, woman, boy, girl, or male/female).
Focus on the character's appearance, gestures, poses, clothing, and any accessories they might be wearing.
If the character is interacting with any objects, describe the nature of the interaction clearly, including interactions with the background.
Describe the character's expressions and emotions.
Mention any text visible on the character or objects (e.g., logos, patterns, or labels).
Specify the lighting’s direction, intensity, and its effect on the character (e.g., shadows or highlights on the body or clothing).
Indicate the style of the image (e.g., cartoon, photograph, 3D render) and avoid adding subjective interpretations or speculation. Keep the description strictly factual and focus solely on the observable details within the image.
Below are some sample images with their generated captions.


3 | Towards the Approach
Existing methods struggle to generate characters in diverse poses, facial expressions, and varying backgrounds using a single model with just a reference character image and prompt description—an open problem to date. To address this, and in alignment with Dashtoon’s custom requirements and internal workflow for comic creation, we viewed the problem through the lens of inpainting, leveraging its suitability for our structured comic creation process.
Formally, the objective is to repurpose a text-to-image generative model for ID-consistent character inpainting. The task involves generating an inpainted image by utilizing user-provided inputs, including a base image, a binary mask defining the region to be inpainted, a reference image specifying the identity and appearance of the character, and a textual prompt describing the final inpainted image. The approach should ensure that the inpainted character maintains identity consistency with the reference image, adheres to the attributes specified in the prompt, and integrates seamlessly into the masked region of the base image.
We chose SDXL [12] for this research to meet our specific requirements; however, the proposed method is adaptable and can be extended to other text-to-image models, including Diffusion Transformer-based models such as Flux [15], SD3.5 [17], and others.
3.1 | Preliminaries
3.1.1 | Cross-Attention
In text-to-image models such as Stable Diffusion, text conditioning is achieved through the cross-attention mechanism, where CLIP-generated text embeddings are integrated into the cross-attention layers to guide the generation process. Formally,

Theoretically, this cross-attention mechanism can be extended to incorporate information from other modalities, provided that the information can be effectively projected into the model’s cross-attention embedding space. Let’s discuss this further in the next subsection.
3.1.2 | Extending Cross-Attention for Image Conditioning
Reference-based text-to-image generation requires that we are effectively able to inject identity information in the base diffusion model through some form of conditioning for ID awareness. IP-Adapter [1] introduced a novel mechanism to enable a pretrained text-to-image diffusion model to generate images with image as a prompt. This is characterized by utilizing a decoupled-cross attention mechanism to inject image features through additional cross-attention layer in the base model along with the text cross-attention layer. Formally, that means:

While [1] demonstrates the addition of image features through a dedicated cross-attention layer (let’s call it ICA1) for image conditioning, we can further extend this concept to include more cross-attention layers, each injecting different modalities into the base model to provide supplementary information that might not be fully captured by the earlier ones.
However, the point to consider here is that cross-attention extension essentially operates as a weighted addition, which inherently dilutes the information being integrated. Consequently, the more cross-attention layers we add, the greater the risk of diminishing the distinctiveness of the injected information. However, through our experiments and empirical observations, we found that adding yet another cross-attention layer actually helped in providing additional information that was not captured by the initial image cross-attention layer.
We will discuss more on this in the upcoming sections.
3.2 | Method Discussion
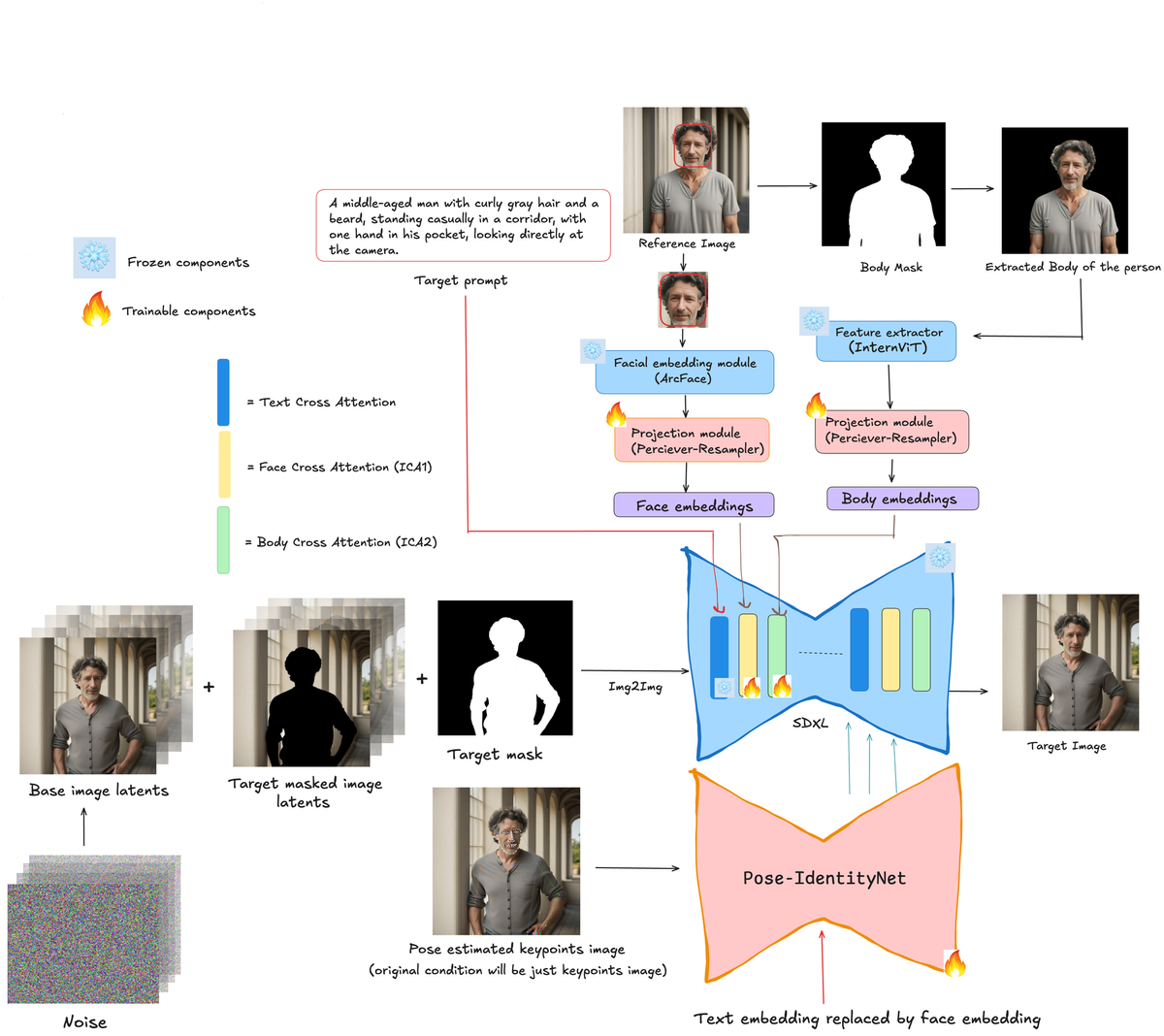
![Fig 8: Overview of the proposed framework for ID-consistent character inpainting. Reference images are processed to extract facial and body embeddings using specialized modules (ArcFace and InternViT, respectively), which are projected into the SDXL’s text embedding space and injected into SDXL as extra cross-attention layers (ICA1 for facial features and ICA2 for global body-level features). Pose-IdentityNet further refines the output by replacing text embeddings with face embeddings (following [2]) to ensure accurate identity preservation and pose adherence by virtue of being conditioned on pose keypoints images.](https://content.dashtoon.ai/assets/free-id-consistent-character/diag1b-1.png)
3.2.1 | SDXL for inpainting
To adapt SDXL for the inpainting task, we followed the standard approach of utilizing 9-channel inputs for the U-Net backbone. The base input image and the masked image were encoded into 4-channel latents using the SDXL VAE, with the masked image downsampled according to the SDXL VAE's scale factor. These components were then concatenated in the following order: image latents + mask + masked image latents, forming the final input to the U-Net.
3.2.2 | Injecting ID information - Facial Features
To incorporate identity information into the SDXL U-Net, we divide the process into two parts. In the first part, we employ an ArcFace module (antelope-v2) [3] to extract facial features from the reference image. These features are then projected into the SDXL cross-attention embedding space via a trainable projection module known as the Perceiver-Resampler [4]. The Perceiver-Resampler accepts input image features and transforms them into a fixed number of learnable queries, which serve as the output feature sequence. These features are subsequently used to extract key and value embeddings, and are then combined with the queries obtained from self-attention to form the final cross-attention mechanism, following the approach described in [1].
In the second part, we follow the approach outlined in [2] to enhance face-ID information within SDXL. Specifically, we employ the ControlNet (or IdentityNet) described in [2], initialized from the same checkpoint. In this setup, text embeddings are replaced with the facial embeddings extracted in the first part, ensuring the network focuses exclusively on face information for improved identity awareness.
3.2.3 | Injecting Pose information
In the original IdentityNet framework described in [2], five facial keypoints (two for the eyes, one for the nose, and two for the mouth) are used as the conditioning image to provide spatial control information to the ControlNet. However, in the context of our problem space, this approach proved suboptimal, as it confines the facial region strictly to the layout of the user reference image. Moreover, the facial expressions of the reference image are perpetuated in the generation process (see Fig. 9). This outcome is at odds with our goal, which requires the generated image to conform to the target character’s pose and facial expressions requiring inpainting.

Hence, we opted to extract 133 pose keypoints set in the OpenPose format for the character defined by the mask region in the user-provided base image, which is to be inpainted with the character from the reference image. The extracted keypoint image (Fig 10) is then provided to our version of IdentityNet, referred to as Pose-IdentityNet. This approach offers additional pose information for the target character, while also capturing a richer range of facial expressions through the expanded keypoint set. For this we used RTMPose-l, 384x288 variant (based on MMPose) [5], to extract the required keypoints set. Note that the pose model receives the masked image containing only the target character, allowing keypoints to be extracted exclusively for the intended subject.

3.2.4 | Injecting ID information - Body features
In addition to the facial information supplied to SDXL via cross-attention and Pose-IdentityNet, we introduce an additional cross-attention layer to incorporate more global information about the character from the reference image. This step ensures that the generated outputs fully align with the reference subject’s overall body appearance, including details such as hairstyle. Based on our discussion in Section 3.1.2, we understand that the cross-attention layer in the SDXL U-Net can be further extended to incorporate additional information. Formally, this can be translated as:

The first image cross-attention mechanism is utilized to inject facial ID features, while the second image cross-attention is employed for incorporating global ID features. To extract these global features, we leverage the InternViT-300M-448px [6] model, which processes the segmented character region obtained from the reference image and outputs image embeddings. The extracted features are then passed through a Perceiver-Resampler module, which projects them into the SDXL cross-attention embedding space, similar to what we did for facial ID features.
This straightforward extension enabled the model to better focus on body-related attributes, including physical details, shapes, and hairstyles.
3.2.5 | Training details
Figure 8 provides an overview of the training flow and pipeline, which includes the following trainable components: two Perceiver-Resampler projection modules, a facial ID cross-attention layer, a global ID cross-attention layer, and the entire Pose-IdentityNet. The experiments were conducted using SDXL 1.0 while keeping its base weights frozen. Model training was performed on 8 H100 GPUs (80 GB), with a batch size of one sample per GPU.
Approximately 50k distinct IDs were extracted from movie footage; although each character had multiple images available, only one was used as a reference image and another as the target image, thereby forming the necessary triplet data points (reference image, target image, and target prompt). An additional set of approximately 30k single-image anime IDs was also incorporated; in these cases, a horizontally flipped version of the reference image served as the target image to create the triplet data.
To further enhance generalization, we randomly dropped text, face, and body feature embeddings for classifier-free guidance. We also employed multi-resolution training via aspect-ratio bucketing (following [8]) to support multi-resolution inputs. Additionally, the model was trained on longer descriptive prompts (following [9]), using a maximum token length of 154.
3.3 | Sample Results
From left-to-right or top-to-bottom: Base Image, Mask, Extracted Pose Keypoints (from character in the masked region), Reference Image, Inpainted Image.

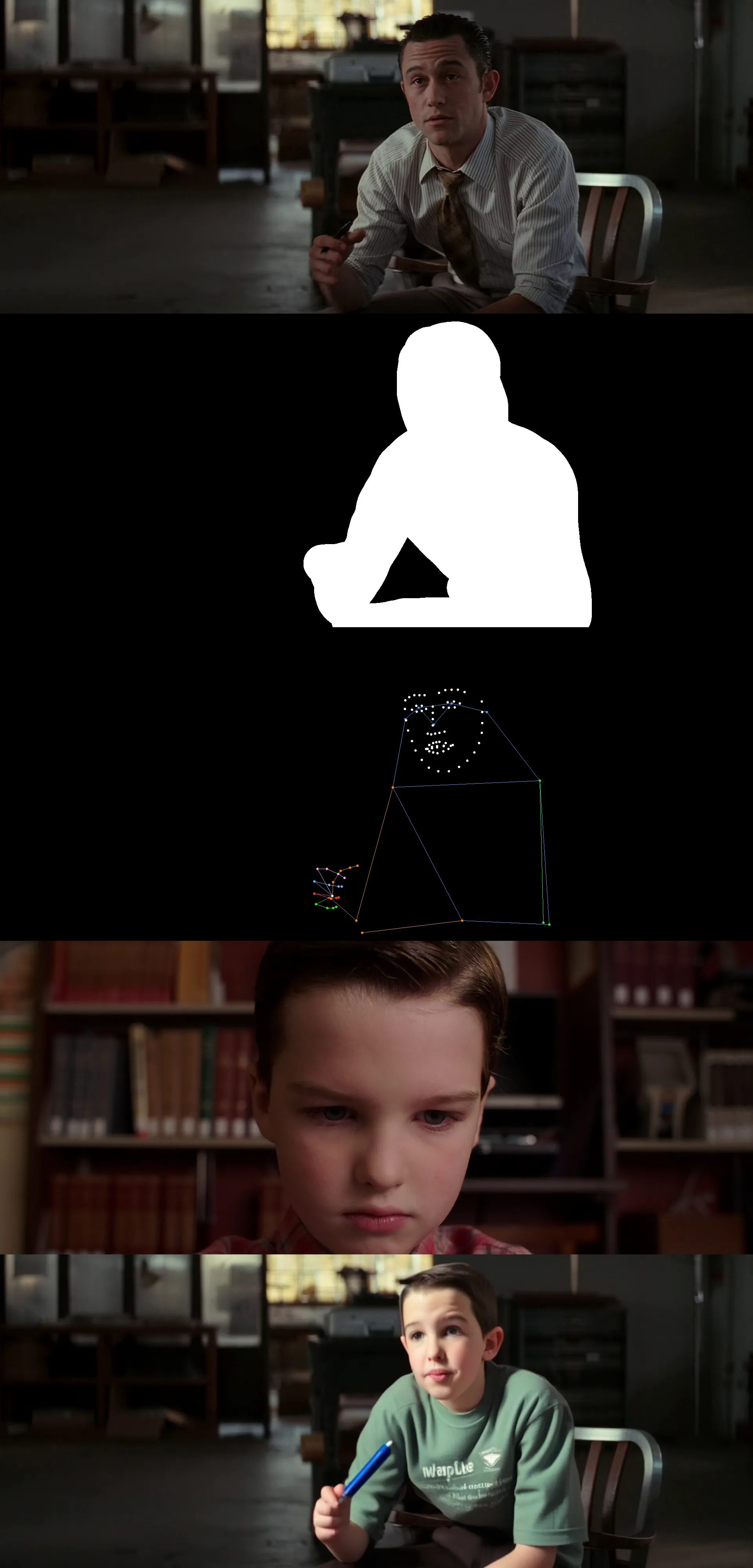
4 | Conclusion
This blogpost presented an approach to Zero-Shot ID-Consistent Character Inpainting, addressing the demands of our comic-creation pipelines. To achieve this goal, we introduced a data construction process that extracts consistent character frames from large-scale movie datasets, thereby enabling robust ID-consistent character training on in-the-wild images (flexible reference images which doesn’t need to be portrait as shown in sample results). Our proposed inpainting architecture integrates additional cross-attention over global image features, ensuring the faithful injection of the reference character’s physical attributes. Furthermore, we incorporated a pose-conditioned ControlNet to promote accurate pose and facial attribute adherence—an essential requirement for high-fidelity character inpainting. To the best of our knowledge, this is the first work to explicitly focus on zero-shot ID-preserving character inpainting. The empirical results underscore the effectiveness of our approach in maintaining character identity and pose alignment.
We also encountered challenges with our proposed model. One primary issue is color saturation (Fig 14), an artifact carried over from the InstantID-based ideas that we leveraged, which is similarly reflected in our outputs. Additionally, the model sometimes struggles with rendering complex hairstyles (Fig 15), indicating the need for more robust handling of fine-grained attributes. Lastly, the reliance on external modules such as ArcFace and pose extraction introduces potential failure points, as inaccuracies in these priors affect subsequent stages of the generation pipeline.

4.1 | Scaling data with the synthetic images
As discussed earlier, recent advancements in training-free approaches have demonstrated promising results for achieving ID consistency. These methods tend to leverage cross-image attention manipulations across batches to maintain consistency effectively. A notable example is [14], which also employs Diffusion Features (DIFT) [16] to establish dense visual correspondences across images, ensuring that the subject appears consistent across different generations.
In the context of data generation for training the architecture proposed in this work, the approach outlined in [14] can be effectively leveraged to further scale the dataset. By providing unique character descriptions—generated based on specific requirements and utilizing available LLMs—to the model, and enabling the generation of batches of two or more consistent images under varying prompt settings, it can serve as strong medium to facilitate the creation of diverse training samples.
What Next - Efforts on training-free approaches
As discussed in the preceding section, we are concurrently exploring training-free approaches for zero-shot ID-consistent character synthesis, not only for data scaling but also with the goal of adapting them to support reference images, inpainting, and other tools integral to the character creation process.
Recent flow-based methods, such as Flux [15], also present a promising foundation for achieving training-free ID-consistent character generation, owing to their better prompt adherence and anatomy fidelity. Our research efforts, therefore, also focus on advancing strategies for encoding reference image information and improving consistency mechanisms within these flow-based models.
Glimpse of what we are currently cooking:


Stayed tuned..!
References
[1] IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
[2] InstantID: Zero-shot Identity-Preserving Generation in Seconds
[3] ArcFace: Additive Angular Margin Loss for Deep Face Recognition
[4] Flamingo: a Visual Language Model for Few-Shot Learning
[5] RTMPose: Real-Time Multi-Person Pose Estimation based on MMPose
[6] OpenGVLab-InternVL
[7] Segment Anything (SAM)
[8] PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation
[9] kohya-ss sd scripts - SDXL training
[10] DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
[11] An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
[12] SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
[13] PuLID: Pure and Lightning ID Customization via Contrastive Alignment
[14] ConsiStory: Training-Free Consistent Text-to-Image Generation
[15] Flux
[16] Emergent Correspondence from Image Diffusion
[17] Stable Diffusion 3.5
[18] DALL-E3
[19] High-Resolution Image Synthesis with Latent Diffusion Models